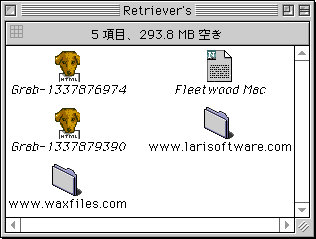
Web Retrieverを設定する前に、ハードディスク上にWeb Retrieverが利用するフォルダを用意しよう。ここでは「Retriever’s」という名前を付けた。
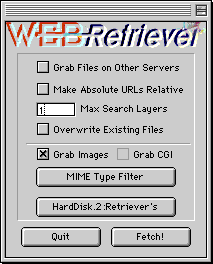
Web Retrieverを起動すると、画面11のようなウィンドウが開く。このウィンドウが設定画面と実行画面を兼ねているので、設定にとりかかろう。[Grab Files on Other servers]は、ターゲットとするページからほかのサーバにリンクが張ってある場合、そのリンクをたどってダウンロードするかどうかを設定する。通常はチェックを外しておいてよいだろう。


 特価デジ物
特価デジ物
 ブラウザゲーム
ブラウザゲーム フリーゲーム
フリーゲーム Windows7
Windows7 ちょい読み!
ちょい読み!