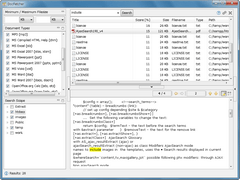
文字列の一括検索といえば、プレーンテキストを対象としたGrepソフトが一般的だが、「DocFetcher」は、さらにMicrosoft OfficeやOpenOffice.org(Apache OpenOffice)、PDF、JPEG画像内のExif情報といったものまで扱えるのがなによりの魅力。前提としてインデックスファイルをあらかじめ作成しておく必要があるが、事前に予想していたよりかなり高速。もちろん対象となるファイル数にもよるが、作成にそれほど待たされることはなさそうだ。「Search Scope」には、作成したインデックス(のルートフォルダ名)が表示される。もちろん複数のインデックスを登録することが可能。実際に検索を行う際には、使用するインデックスにマークすればよい。インデックス内のサブフォルダ(すなわち対象フォルダ内のサブフォルダ)もマークのON/OFFで検索対象を指定することができる。インデックスの更新や再構築も簡単なので、業務の合間や一日の終わりに更新しておけば、新規に作成した文書もすぐに検索で利用できるはずだ。
英語版のソフトなので、インデックス作成時のダイアログの内容などは多少わかりにくい部分もあるが、とりあえずは検索対象のルートフォルダを指定しておけばよいようだ。検索そのものは文字列(もちろん日本語も可)を入力し、「Search」ボタンをクリックするだけなので、まったく問題はない。
検索キーワードを複数指定した場合、初期状態ではOR検索になる。もちろんオプションでAND検索に切り替えることができる。この条件設定がもっと柔軟にできれば、さらに強力なソフトになるのではないかと感じた。また、HTMLビューアではハイライト表示とキーワードのジャンプができないのはちょっと残念。HTMLモードをOFFにして、ベーシックなテキストビューアに切り替えればよいのだが、できればHTMLモードでも利用できるとありがたい。
(福住 護)